本文首次发布于 amazingJing Blog, 作者 @神兵(amazingJing) ,转载请保留原文链接.
使用IDEA搭建Flink1.10.0源码踩过的坑
由于对BigData感兴趣,在学习了Hadoop、MapReduce以及了解Spark相关技术后,准备开展对于Flink的学习,本篇文章主要介绍使用IDEA搭建Flink1.10.0源码运行词频统计例子WordCount过程中遇到的问题,记录下来避免今后在遇到相同问题浪费时间。搭建过程就不再赘述了,百度搜索会有详细介绍,本文主要是记录作者过程中遇到的问题以及解决方法。
-
1.找不到依赖io.confluent:kafka-schema-registry-client:3.3.1
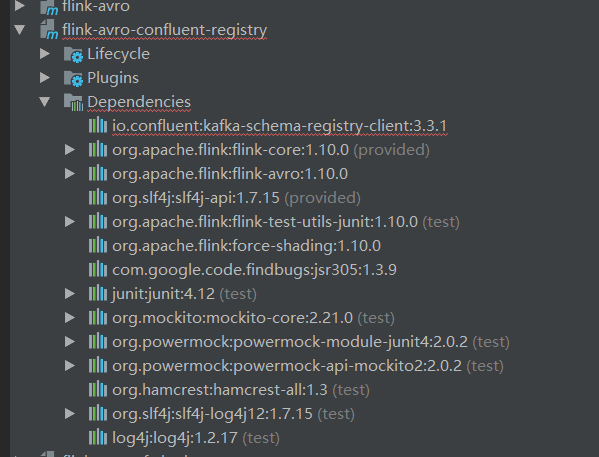
解决办法: 首先登陆MVNRespsitory下载相关的jar,这里会发现找不到3.3.1版本的包,所以我选择了3.3.2版本包。下载完成后,通过命令行安装进行安装。
mvn install:install-file -Dfile=D:\JHH\myMavenRepo\kafka-schema-registry-client-3.3.2.jar -DgroupId=io.confluent -DartifactId=kafka- schema-registry-client -Dversion=3.3.2 -Dpackaging=jar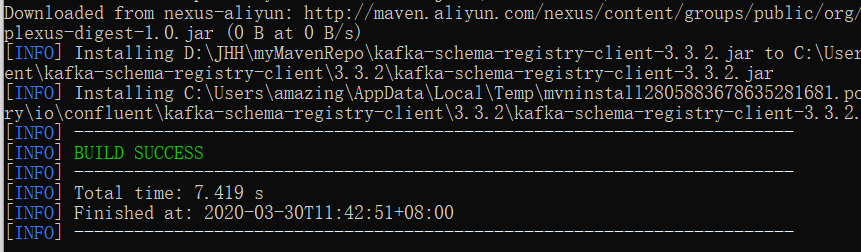
-
2.org.codehaus.mojo:build-helper-maven-pligin:
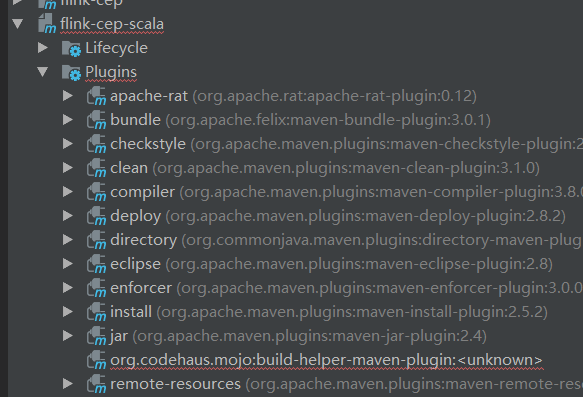 解决办法:在对应的pom.xml文件中加入版本号
3.0.3 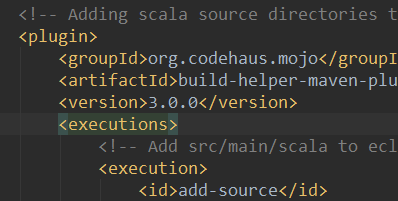
-
3.maven依赖没有问题后,build项目时报错import org.apache.flink.sql.parser.impl.FlinkSqlParserImpl;发现项目中果真没有这个文件。
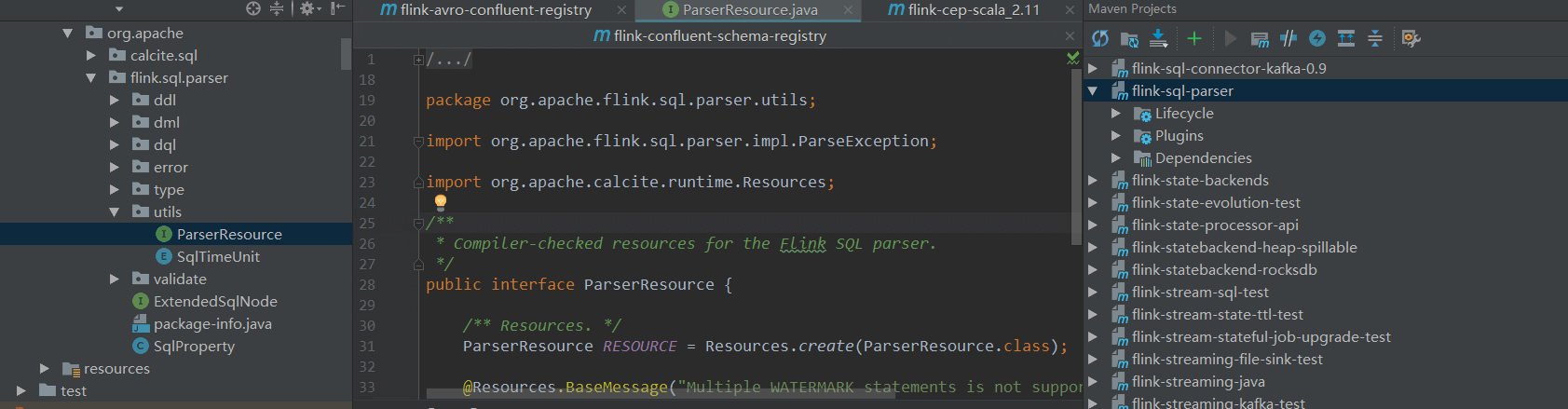 解决办法:通过idea对相应模块generate sources,一次可能不成功,建议多尝试几次。
解决办法:通过idea对相应模块generate sources,一次可能不成功,建议多尝试几次。 -
4.与Avro有依赖关系的类文件找不到由Avro框架根据.avsc文件生成的对应的.java文件
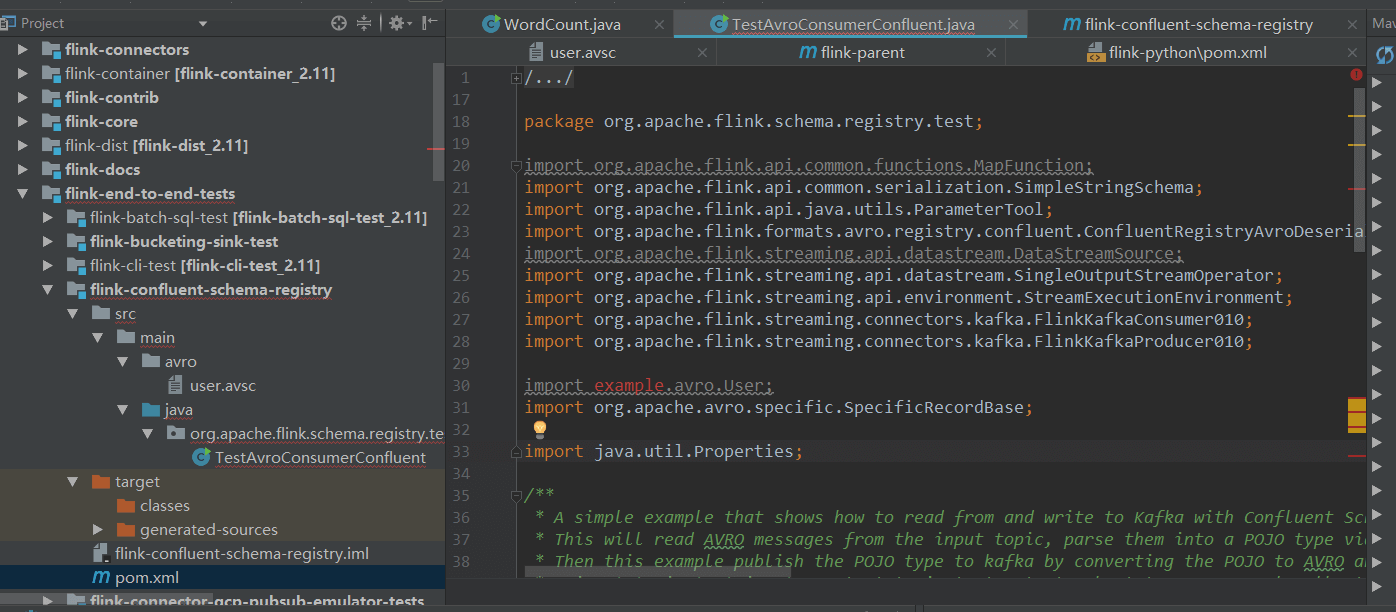
解决方法:通过maven编译对应模块,就可以找到对应的文件。
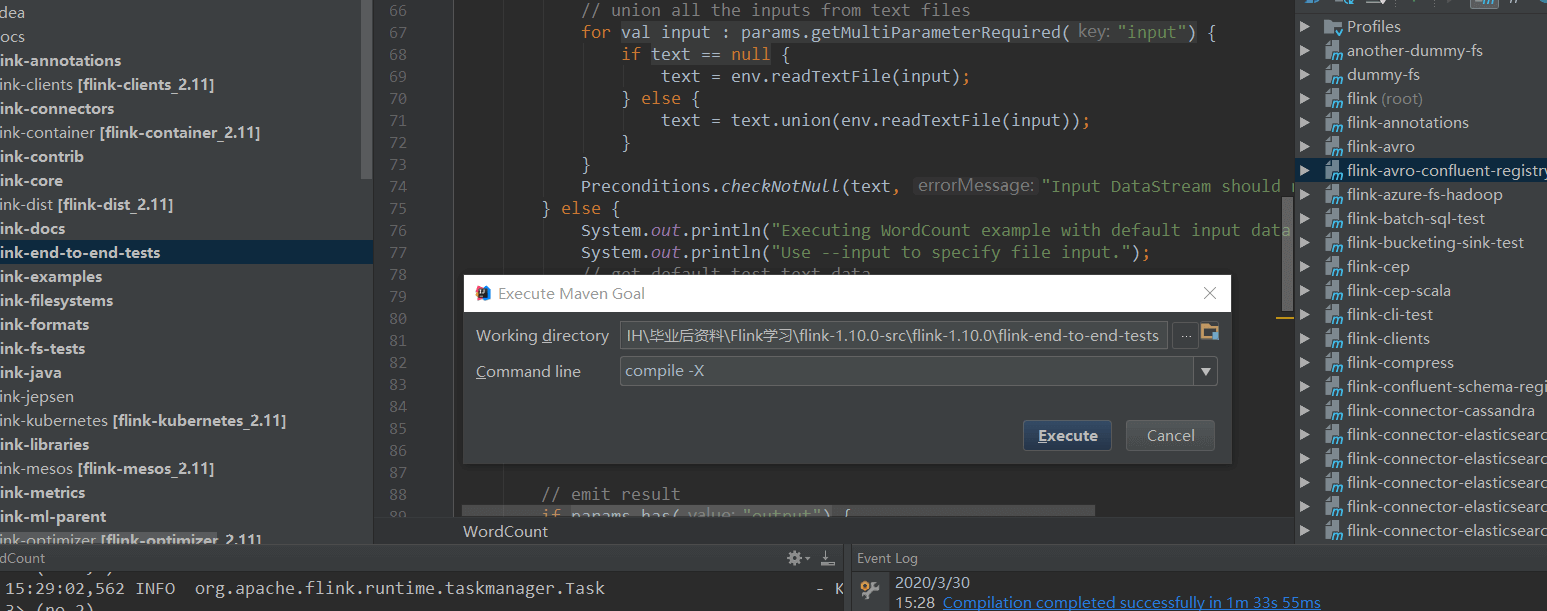
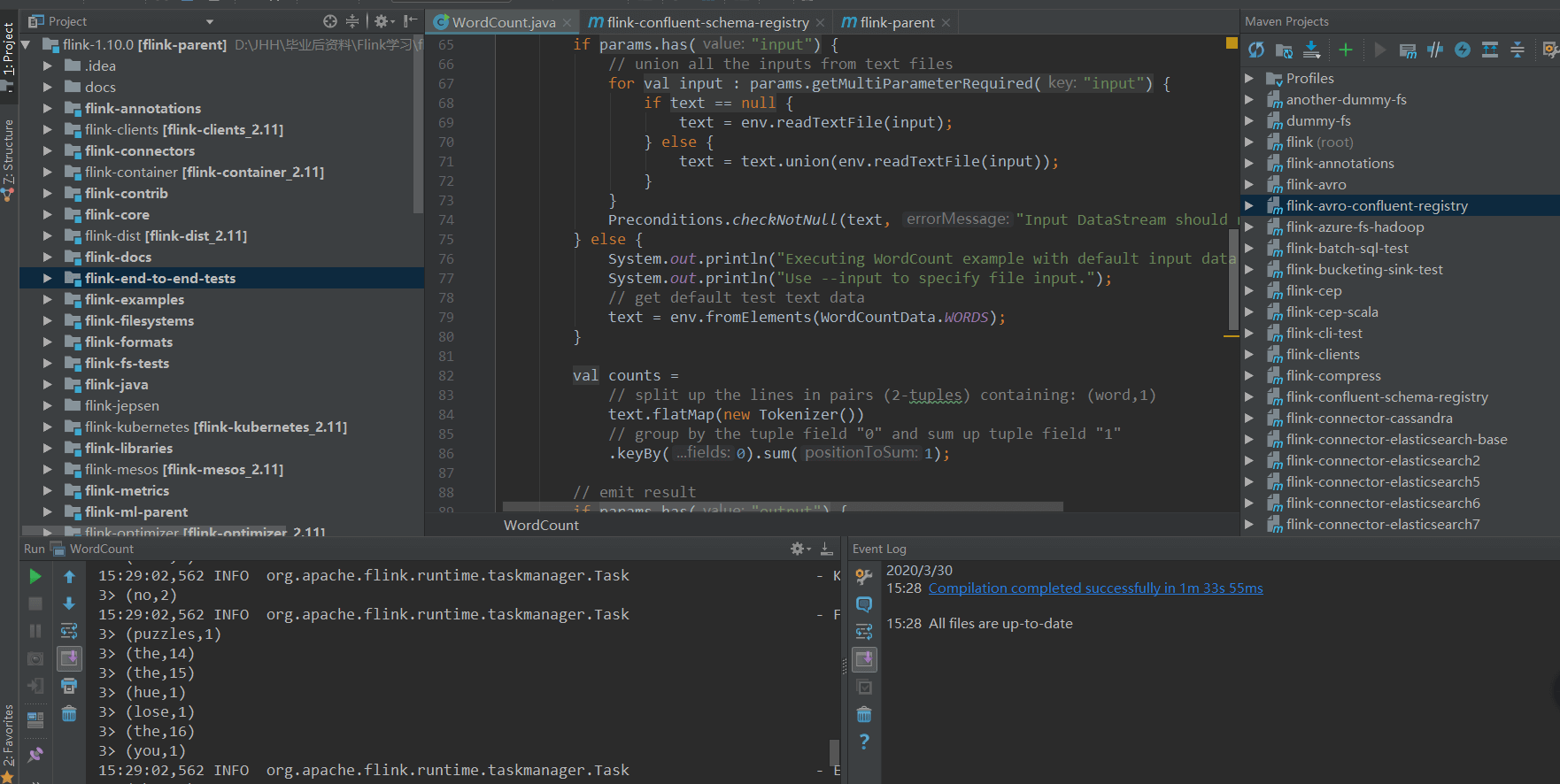
最后,通过运行Flink官网自带的Examples中的WordCount,检验代码成功运行,就可以愉快地调试源码了。
关于Flink的学习,推荐自认为优秀的网站: